

Over the last few years, I have experimented with various flavors of userland, kernel-bypass networking. In this article, we’ll take FD.IO for a spin.
We will compare the result with the results of my last blog in which we looked at how much a vanilla Linux kernel could do in terms of forwarding (routing) packets. We observed that on Linux, to achieve 14Mpps we needed roughly 16 and 26 cores for a unidirectional and bidirectional test. In this article, we’ll look at what we need to accomplish this with FD.io
Userland networking
The principle of Userland networking is that the networking stack is no longer handled by the kernel, but instead by a userland program. The Linux kernel is incredibly feature-rich, but for fast networking, it also requires a lot of cores to deal with all the (soft) interrupts. Several of the userland networking projects rely on DPDK to achieve incredible numbers. One reason why DPDK is so fast is that it doesn’t rely on Interrupts. Instead, it’s a poll mode driver. Meaning it’s continuously spinning at 100% picking up packets from the NIC. A typical server nowadays comes with quite a few CPU cores, and dedicating one or more cores for picking packets of the NIC is, in some cases, entirely worth it. Especially if the server needs to process lots of network traffic.
So DPDK provides us with the ability to efficiently and extremely fast, send and receive packets. But that’s also it! Since you’re not using the kernel, we now need a program that takes the packets from DPDK and does something with it. Like for example, a virtual switch or router.
FD.IO

FD.IO is an open-source software dataplane developed by Cisco. At the heart of FD.io is something called Vector Packet Processing (VPP).
The VPP platform is an extensible framework that provides switching and routing functionality. VPP is built on a ‘packet processing graph.’ This modular approach means that anyone can ‘plugin’ new graph nodes. This makes extensibility rather simple, and it means that plugins can be customized for specific purposes.
FD.io can use DPDK as the drivers for the NIC and can then process the packets at a high performant rate that can run on commodity CPU. It’s important to remember that it is not a fully-featured router, ie. it doesn’t really have a control plane; instead, it’s a forwarding engine. Think of it as a router line-card, with the NIC and the DPDK drivers as the ports. VPP allows us to take a packet from one NIC to another, transform it if needed, do table lookups, and send it out again. There are API’s that allow you to manipulate the forwarding tables. Or you can use the CLI to, for example, configure static routes, VLAN, vrf’s etc.
Test setup
I’ll use mostly the same test setup as in my previous test. Again using two n2.xlarge.x86 servers from packet.com and our DPDK traffic generator. The set up is as below.
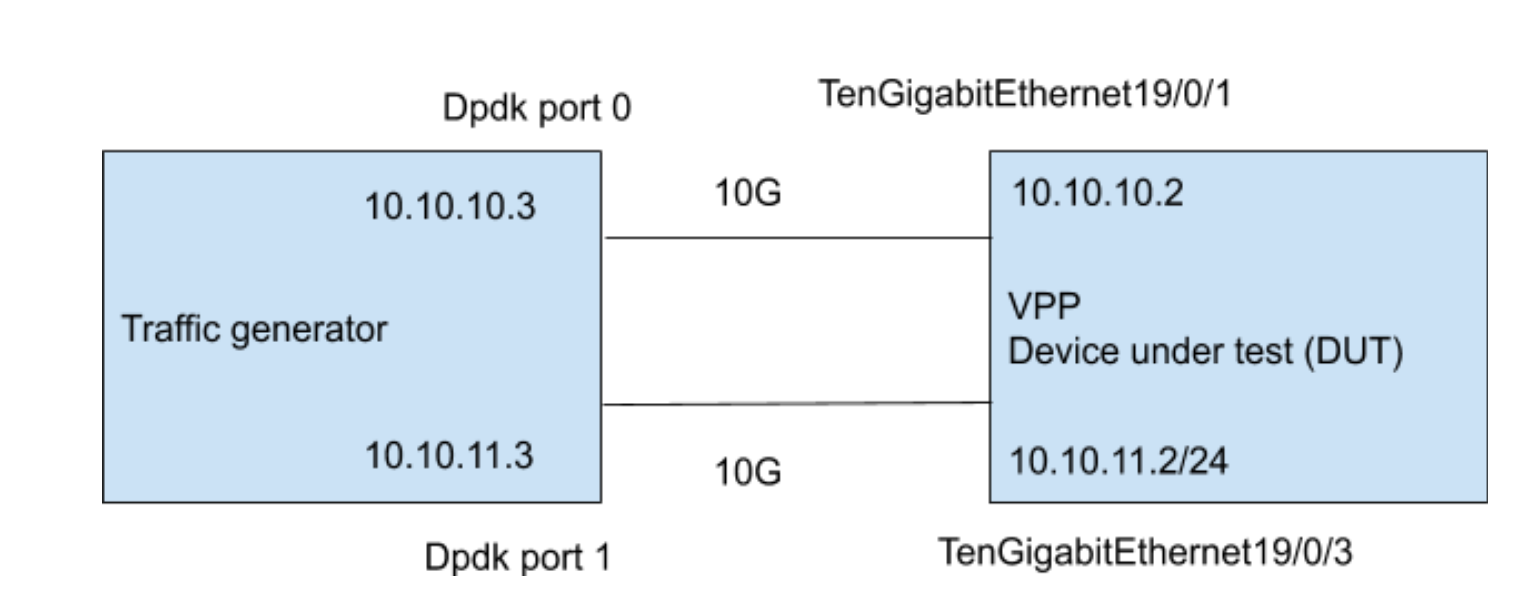
I’m using the VPP code from the FD.io master branch and installed it on a vanilla Ubuntu 18.04 system following these steps.
Test results — Packet forwarding using VPP
Now that we have our test setup ready to go, it’s time to start our testing!
To start, I configured VPP with “vppctl” like this, note that I need to set static ARP entries since the packet generator doesn’t respond to ARP.
set int ip address TenGigabitEthernet19/0/1 10.10.10.2/24
set int ip address TenGigabitEthernet19/0/3 10.10.11.2/24
set int state TenGigabitEthernet19/0/1 up
set int state TenGigabitEthernet19/0/3 up
set ip neighbor TenGigabitEthernet19/0/1 10.10.10.3 e4:43:4b:2e:b1:d1
set ip neighbor TenGigabitEthernet19/0/3 10.10.11.3 e4:43:4b:2e:b1:d3
That’s it! Pretty simple right?
Ok, time to look at the results just like before we did a single flow test, both unidirectional and bidirectional, as well as a 10,000 flow test.
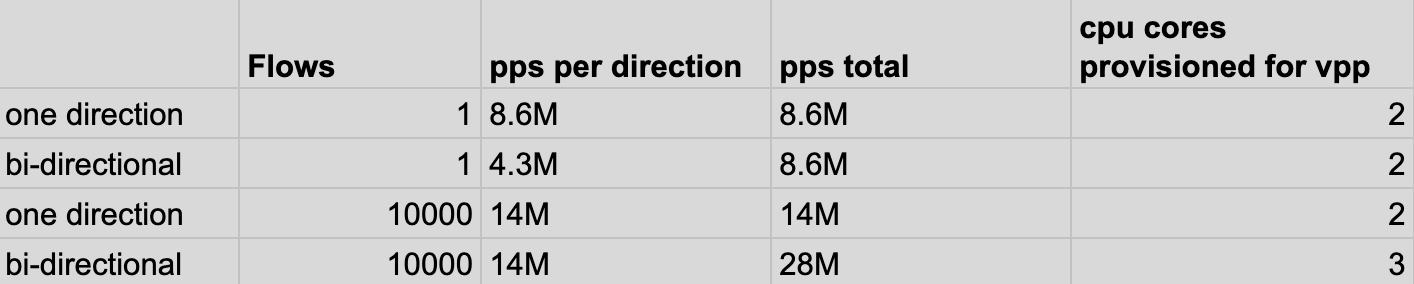
Those are some remarkable numbers! With a single flow, VPP can process and forward about 8Mpps, not bad. The perhaps more realistic test with 10,000 flows, shows us that it can handle 14Mpps with just two cores. To get to a full bi-directional scenario where both NICs are sending and receiving at line rate (28 Mpps per NIC) we need three cores and three receive queues on the NIC. To achieve this last scenario with Linux, we needed approximately 26 cores. Not bad, not bad at all!

Test results — NAT using VPP
In my previous blog we saw that when doing SNAT on Linux with iptables, we got as high as 3Mpps per direction needing about 29 CPUs per direction. This showed us that packet rewriting is significantly more expensive than just forwarding. Let’s take a look at how VPP does nat.
To enable nat on VPP, I used the following commands:
nat44 add interface address TenGigabitEthernet19/0/3
nat addr-port-assignment-alg default
set interface nat44 in TenGigabitEthernet19/0/1 out TenGigabitEthernet19/0/3 output-featureMy first test is with one flow only in one direction. With that, I’m able to get 4.3Mpps. That’s’ exactly half of what we saw in the performance test without nat. It’s no surprise this is slower due to the additional work needed. Note that with Linux iptables I was seeing about 1.1Mpps.
A single flow for nat isn’t super representative of a real-life nat example where you’d be translating many sources. So for the next measurements, I’m using 255 different source IP addresses and 255 destination IP addresses as well as different port numbers; with this setup, the nat code is seeing about 16k sessions. I can now see the numbers go to 3.2Mpps; more flows mean more nat work. Interestingly, this number is exactly the same as I saw with iptables. There is however one big difference, with iptables the system was using about 29 cores. In this test, I’m only using two cores. That’s a low number of workers, and also the reason I’m capped. To remove that cap, I added more cores and validated that the VPP code scales horizontally. Eventually, I need 12 cores to run 14Mpps for a stable experience.

Below is the relevant VPP config to control the number of cores used by VPP. Also, I should note that I isolated the cores I allocated to VPP so that the kernel wouldn’t schedule anything else on it.
cpu {
main-core 1
# CPU placement:
corelist-workers 3–14
# Also added this to grub: isolcpus=3-31,34-63
}
dpdk {
dev default {
# RSS, number of queues
num-rx-queues 12
num-tx-queues 12
num-rx-desc 2048
num-tx-desc 2048
}
dev 0000:19:00.1
dev 0000:19:00.3
}
plugins {
plugin default { enable }
plugin dpdk_plugin.so { enable }
}
nat {
endpoint-dependent
translation hash buckets 1048576
translation hash memory 268435456
user hash buckets 1024
max translations per user 10000
}Conclusion

In this blog, we looked at VPP from the FD.io project as a userland forwarding engine. VPP is one example of a kernel bypass method for processing packets. It works closely with and further augments DPDK.
We’ve seen that the VPP code is feature-rich, especially for a kernel bypass packet forwarder. Most of all, it’s crazy fast.
We need just three cores to have two NICs forward full line-rate (14Mpps) in both directions. Comparing that to the Linux kernel, which needed 26 cores, we see an almost 9x increase in performance.
We noticed that the results were even better when using nat. In Linux, I wasn’t able to get any higher than 3.2Mpps for which I needed about 29 cores. With VPP we can do 3.2Mpps with just two cores and get to full line rate nat with 12 cores.
I think FD.io is an interesting and exciting project, and I’m a bit surprised it’s not more widely used. One of the reasons is likely that there’s a bit of a learning curve. But if you need high-performance packet forwarding, it’s certainly something to explore! Perhaps this is the start of your VPP project? if so, let me know!
Cheers
-Andree





