

Loyal readers of my blog will have noticed a theme, I’m interested in the continued move to virtualized network functions, and the need for faster networking options on cloud compute. In this blog, we’ll look at the network performance on the juggernaut of cloud computing, AWS.
AWS is the leader in the cloud computing world, and many companies now run parts of their services on AWS. The question we’ll try to answer in this article is: how well suited is AWS’ ec2 for high throughput network functions.
I’ve decided to experiment with adding a short demo video to this blog. Below you will find a quick demo and summary of this article. Since these videos are new and a bit of an experiment, let me know if you like it.
100G networking
It’s already been two years since AWS announced the C5n instances, featuring 100 Gbps networking. I’m not aware of any other cloud provider offering 100G instances, so this is pretty unique. Ever since this was released I wondered exactly what, if any, the constraints were. Can I send/receive 100g line rate (144Mpps)? So, before we dig into the details, let’s just check if we can really get to 100Gbs.
this is fun :) 97Gbs pic.twitter.com/6VdkR2Rlr4
— Andree Toonk, Adelante! (@atoonk) May 28, 2020
There you have it, I was able to get to 100Gbs between 2 instances! That’s exciting. But there are a few caveats. We’ll dig into all of them in this article, with the aim to understand exactly what’s possible, what the various limits are, and how to get to 100g.
Understand the limits
Network performance on Linux is typically a function of a few parameters. Most notably, the number of TX/RX queues available on the NIC (network card). The number of CPU cores, ideally at least equal to the number of queues. The pps (packets per second) limit per queue. And finally, in virtual environments like AWS and GCP, potential admin limits on the instance.

Doing networking in software means that processing a packet (or a batch of them) uses a number of CPU cycles. It’s typically not relevant how many bytes are in a packet. As a result, the best metric to look at is the: pps number (related to our cpu cycle budget). Unfortunately, the pps performance numbers for AWS aren’t published so, we’ll have to measure them in this blog. With that, we should have a much better understanding of the network possibilities on AWS, and hopefully, this saves someone else a lot of time (this took me several days of measuring) ;)
Network queues per instance type
The table below shows the number of NIC queues by ec2 (c5n) Instance type.

In the world of ec2, 16 vCPUs on the C5n 4xl instance means 1 Socket, 8 Cores per socket, 2 Threads per core.
On AWS, an Elastic Network Adapter (ENA) NIC has as many queues as you have vCPUs. Though it stops at 32 queues, as you can see with the C5n 9l and C5n 18xl instance.
Like many things in computing, to make things faster, things are parallelized. We see this clearly when looking at CPU capacity, we’re adding more cores, and programs are written in such a way that can leverage the many cores in parallel (multi-threaded programs).
Scaling Networking performance on our servers is done largely the same. It’s hard to make things significantly faster, but it is easier to add more ‘workers’, especially if the performance is impacted by our CPU capacity. In the world of NICs, these ‘workers’ are queues. Traffic send and received by a host is load-balanced over the available network queues on the NIC. This load balancing is done by hashing (typically the 5 tuples, protocol, source + destination address, and port number). Something you’re likely familiar with from ECMP.

So queues on a NIC are like lanes on a highway, the more lanes, the more cars can travel the highway. The more queues, the more packets (flows) can be processed.
Test one, ENA queue performance
As discussed, the network performance of an instance is a function of the number of available queues and cpu’s. So let’s start with measuring the maximum performance of a single flow (queue) and then scale up and measure the pps performance.
In this measurement, I used two c5n.18xlarge ec2 instances in the same subnet and the same placement zone. The sender is using DPDK-pktgen (igb_uio). The receiver is a stock ubuntu 20.04 LTS instance, using the ena driver.
The table below shows the TX and RX performance between the two c5n.18xlarge ec2 instances for one and two flows.

With this, it seems the per queue limit is about 1Mpps. Typically the per queue limit is due to the fact that a single queue (soft IRQ) is served by a single CPU core. Meaning, the per queue performance is limited by how many packets per second a single CPU core can process. So again, what you typically see in virtualized environments is that the number of network queues goes up with the number of cores in the VM. In ec2 this is the same, though it’s maxing out at 32 queues.
Test two, RX only pps performance
Now that we determined that the per queue limit appears to be roughly one million packets per second, it’s natural to presume that this number scales up horizontally with the number of cores and queues. For example, the C5n 18xl comes with 32 nic queues and 72 cores, so in theory, we could naively presume that the (RX/TX) performance (given enough flows) should be 32Mpps. Let’s go ahead and validate that.
The graph below shows the Transmit (TX) performance as measured on a c5n.18xlarge. In each measurement, I gave the packet generator one more queue and vcpu to work with. Starting with one TX queue and one VCPu, incrementing this by one in each measurement until we reached 32 vCPU and 32 queues (max). The results show that the per TX queue performance varied between 1Mpps to 700Kpps. The maximum total TX performance I was able to get however, was ~8.5Mpps using 12 TX queues. After that, adding more queues and vCPu’s didn’t matter, or actually degraded the performance. So this indicates that the performance scales horizontally (per queue), but does max out at a certain point (varies per instance type), in this case at 8.5 Mpps
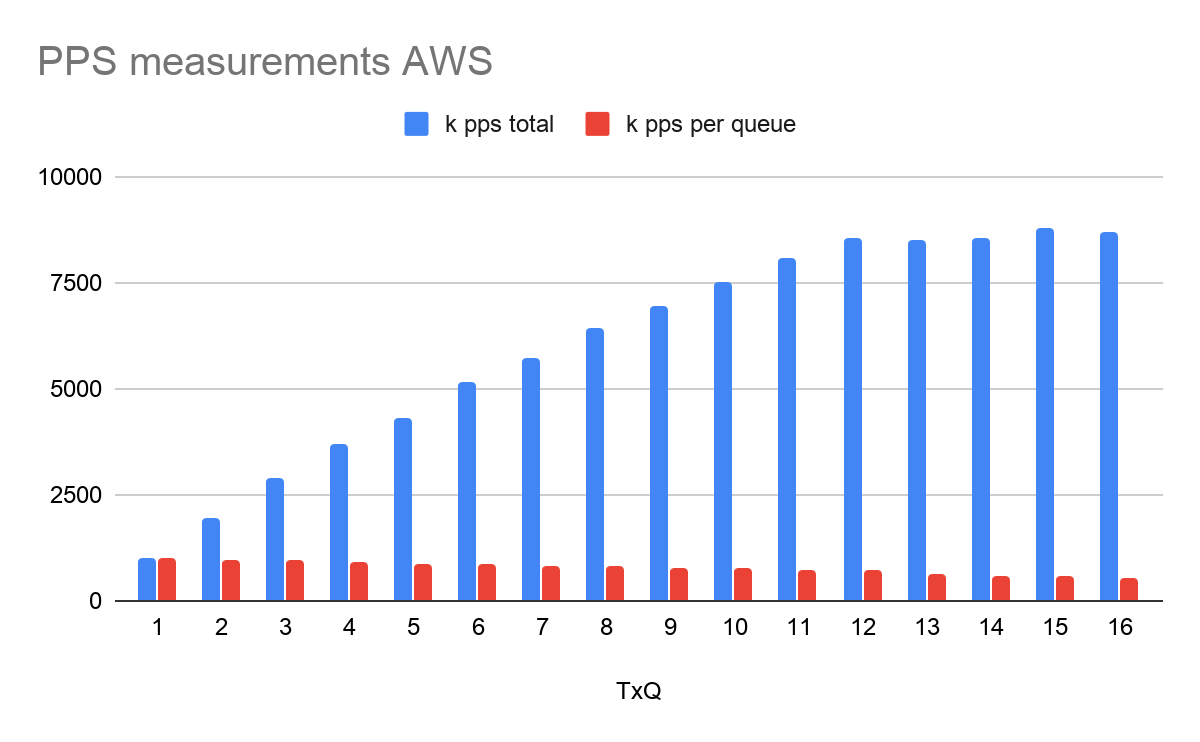
In this next measurement, we’ll use two packet generators and one receiver. I’m using two generators, just to make sure the limit we observed earlier isn’t caused by limitations on the packet generator. Each traffic generator is sending many thousands of flows, making sure we leverage all the available queues.
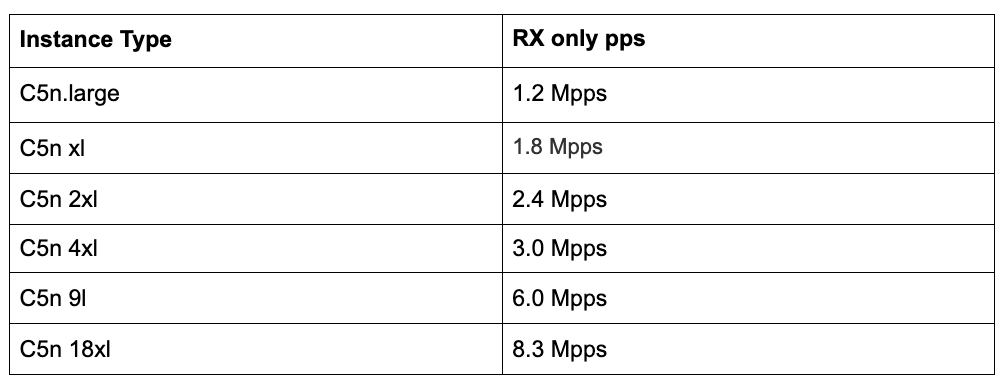
Alright, after a few minutes of reading (and many, many hours, well really days.. of measurements on my end), we now have a pretty decent idea of the performance numbers. We know how many queues each of the various c5n instance types have.
We have seen that the per queue limit is roughly 1Mpps. And with the table above, we now see how many packets per second each instance is able to receive (RX).
Forwarding performance
If we want to use ec2 for virtual network functions, then just receiving traffic isn’t enough. A typical router or firewall should both receive and send traffic at the same time. So let’s take a look at that.
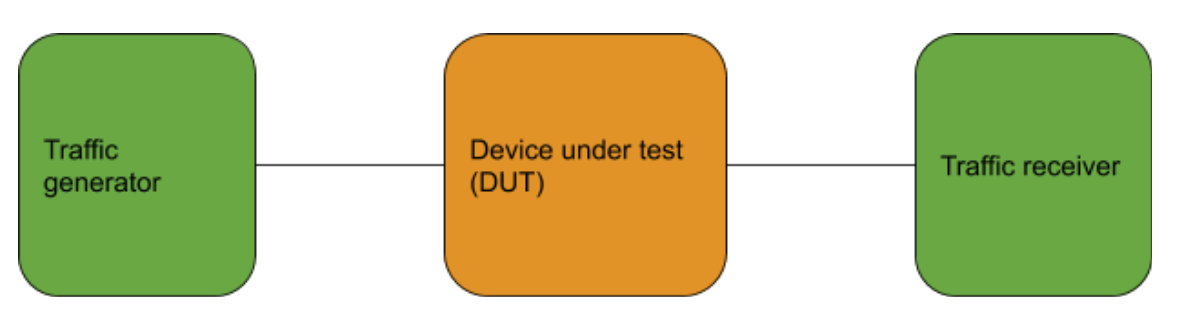
For this measurement, I used the following setup. Both the traffic generator and receiver were C5n-18xl instances. The Device Under Test (DUT) was a standard Ubuntu 20.04 LTS instance using the ena driver. Since the earlier observed pps numbers weren’t too high, I determined it’s safe to use the regular Linux kernel to forward packets.
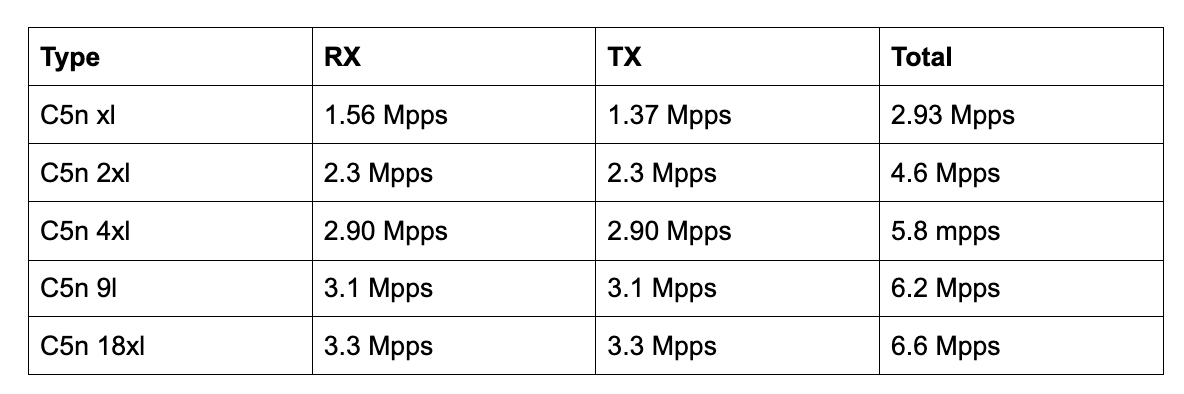
The key takeaway from this measurement is that the TX and RX numbers are similar as we’d seen before for the instance types up to (including) the C5n 4xl. For example, earlier we saw the C5n 4xl could receive up to ~3Mpps. This measurement shows that it can do ~3Mpps simultaneously on RX and TX.
However, if we look at the C5n 9l, we can see it was able to process RX+ TX about 6.2Mpps. Interestingly, earlier we saw it was also able to receive (rx only) ~6Mpps. So it looks like we hit some kind of aggregate limit. We observed a similar limit for the C5n 18xl instance.
In Summary.
In this blog, we looked at the various performance characteristics of networking on ec2. We determined that the performance of a single queue is roughly 1Mpps. We then saw how the number of queues goes up with the higher end instances up until 32 queues maximum.
We then measure the RX performance of the various instances as well as the forwarding (RX + TX aggregate) performance. Depending on the measurement setup (RX, or TX+RX) we see that for the largest instance types, the pps performance maxes out at roughly 6.6Mpps to 8.3Mpps. With that, I think that the C5n 9l hits the sweet spot in terms of cost vs performance.
So how about that 100G test?
Ah yes! So far, we talked about pps only. How does that translate that to gigabits per second?
Let’s look at the quick table below that shows how the pps number translates to Gbs at various packet sizes.

These are a few examples to get to 10G at various packet sizes. This shows that in order to support line-rate 10G at the smallest packet size, the system will need to be able to do ~14.88 Mpps. The 366 byte packet size is roughly the equivalent average of what you’ll see with an IMIX test, for which the systems needs to be able to process ~3,4Mpps to get to 10G line rate.
If we look at the same table but then for 100gbps, we see that at the smallest packet size, an instance would need to be able to process is over 148Mpps. But using 9k jumbo frames, you only need 1.39Mpps.
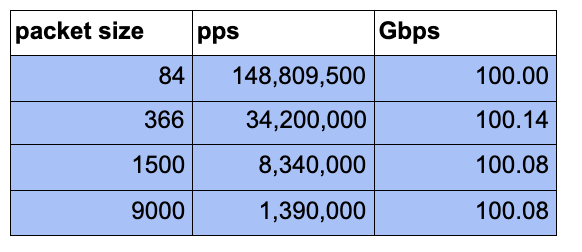
And so, that’s what you need to do to get to 100G networking in ec2. Use Jumbo frames (supported in ec2, in fact, for the larger instances, this was the default). With that and a few parallel flows you’ll be able to get to 100G “easily”!
A few more limits
One more limitation I read about while researching, but didn’t look into myself. It appears that some of the instances have time-based limits on the performance. This blog calls it Guaranteed vs. Best Effort. Basically, you’re allowed to burst for a while, but after a certain amount of time, you’ll get throttled. Finally, there is a per-flow limit of 10Gbs. So if you’re doing things like IPSEC, GRE, VXLAN, etc, note that you will never go any faster than 10g.
Closing thoughts
Throughout this blog, I mentioned the word ‘limits’ quite a bit, which has a bit of a negative connotation. However, it’s important to keep in mind that AWS is a multi-tenant environment, and it’s their job to make sure the user experience is still as much as possible as if the instance is dedicated to you. So you can also think of them as ‘guarantees’. AWS will not call them that, but in my experience, the throughput tests have been pretty reproducible with, say a +/- 10% measurement margin.
All in all, it’s pretty cool to be able to do 100G on AWS. As long as you are aware of the various limitations, which unfortunately aren’t well documented. Hopefully, this article helps some of you with that in the future.
Finally, could you use AWS to run your virtual firewalls, proxies, VPN gateways, etc? Sure, as long as you’re aware of the performance constraints. And with that design a horizontally scalable design, according to AWS best practices. The one thing you really do need to keep an eye on is the (egress) bandwidth pricing, which, when you started doing many gigabits per second, can add up.
Cheers
- Andree





