

One of the oldest protocols and possibly the most used protocol on the Internet today is TCP. You likely send and receive hundreds of thousands or even over a million TCP packets (eeh segments?) a day. And it just works! Many folks believe TCP development has finished, but that’s incorrect. In this blog will take a look at a relatively new TCP congestion control algorithm called BBR and take it for a spin.
Alright, we all know the difference between the two most popular transport protocols used on the Internet today. We have UDP and TCP. UDP is a send and forget protocol. It is stateless and has no congestion control or reliable delivery support. We often see UDP used for DNS and VPNs. TCP is UDP’s sibling and does provide reliable transfer and flow control, as a result, it is quite a bit more complicated.
People often think the main difference between TCP and UDP is that TCP gives us guaranteed packet delivery. This is one of the most important features of TCP, but TCP also gives us flow control. Flow control is all about fairness, and critical for the Internet to work, without some form of flow control, the Internet would collapse.
Over the years, different flow control algorithms have been implemented and used in the various TCP stacks. You may have heard of TCP terms such as Reno, Tahoe, Vegas, Cubic, Westwood, and, more recently, BBR. These are all different congestion control algorithms used in TCP. What these algorithms do is determining how fast the sender should send data while adapting to network changes. Without these algorithms, our Internet pipes would soon be filled with data and collapse.
BBR
Bottleneck Bandwidth and Round-trip propagation time (BBR) is a TCP congestion control algorithm developed at Google in 2016. Up until recently, the Internet has primarily used loss-based congestion control, relying only on indications of lost packets as the signal to slow down the sending rate. This worked decently well, but the networks have changed. We have much more bandwidth than ever before; The Internet is generally more reliable now, and we see new things such as bufferbloat that impact latency. BBR tackles this with a ground-up rewrite of congestion control, and it uses latency, instead of lost packets as a primary factor to determine the sending rate.
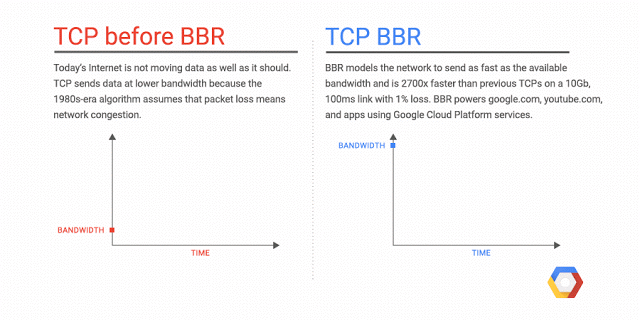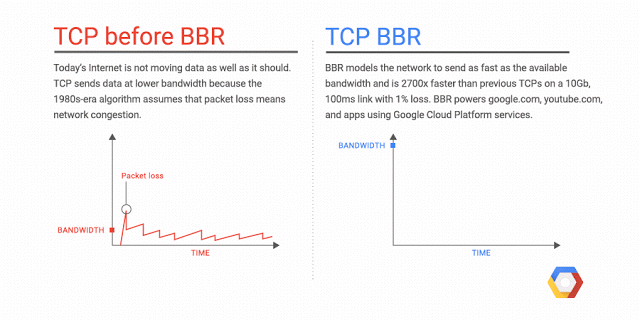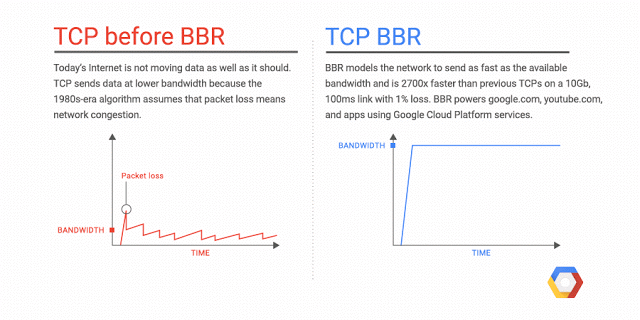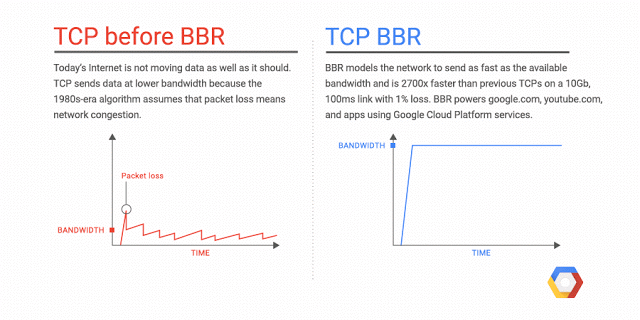
Why is BBR better?
There are a lot of details I’ve omitted, and it gets complicated pretty quickly, but the important thing to know is that with BBR, you can get significantly better throughput and reduced latency. The throughput improvements are especially noticeable on long haul paths such as Transatlantic file transfers, especially when there’s minor packet loss. The improved latency is mostly seen on the last mile path, which is often impacted by Bufferbloat (4 seconds ping times, anyone?). Since BBR attempts not to fill the buffers, it tends to be better in avoiding buffer bloat.

let’s take BBR for a spin!
BBR has been in the Linux kernel since version 4.9 and can be enabled with a simple sysctl command. In my tests, I’m using two Ubuntu machines and Iperf3 to generate TCP traffic. The two servers are located in the same data center; I’m using two Packet.com servers type: t1.small, which come with a 2.5Gbps NIC.
The first test is a quick test to see what we can get from a single TCP flow between the two servers. This shows 2.35Gb/s, which sounds about right, good enough to run our experiments.
The effect of latency on TCP throughput
In my day job, I deal with machines that are distributed over many dozens of locations all around the world, so I’m mostly interested in the performance between machines that have some latency between them. In this test, we are going to introduce 140ms round trip time between the two servers using Linux Traffic Control (tc). This is roughly the equivalent of the latency between San Francisco and Amsterdam. This can be done by adding 70ms per direction on both servers like this:
tc qdisc replace dev enp0s20f0 root netem latency 70msIf we do a quick ping, we can now see the 140ms round trip time
root@compute-000:~# ping 147.75.69.253
PING 147.75.69.253 (147.75.69.253) 56(84) bytes of data.
64 bytes from 147.75.69.253: icmp_seq=1 ttl=61 time=140 ms
64 bytes from 147.75.69.253: icmp_seq=2 ttl=61 time=140 ms
64 bytes from 147.75.69.253: icmp_seq=3 ttl=61 time=140 msOk, time for our first tests, I’m going to use Cubic to start, as that is the most common TCP congestion control algorithm used today.
sysctl -w net.ipv4.tcp_congestion_control=cubicA 30 second iperf shows an average transfer speed of 347Mbs. This is the first clue of the effect of latency on TCP throughput. The only thing that changed from our initial test (2.35Gbs) is the introduction of 140ms round trip delay. Let’s now set the congestion control algorithm to bbr and test again.
sysctl -w net.ipv4.tcp_congestion_control=bbrThe result is very similar, the 30seconds average now is 340Mbs, slightly lower than with Cubic. So far no real changes.
The effect of packet loss on throughput
We’re going to repeat the same test as above, but with the addition of a minor amount of packet loss. With the command below, I’m introducing 1,5% packet loss on the server (sender) side only.
tc qdisc replace dev enp0s20f0 root netem loss 1.5% latency 70msThe first test with Cubic shows a dramatic drop in throughput; the throughput drops from 347Mb/s to 1.23 Mbs/s. That’s a ~99.5% drop and results in this link basically being unusable for today’s bandwidth needs.
If we repeat the exact same test with BBR we see a significant improvement over Cubic. With BBR the throughput drops to 153Mbs, which is a 55% drop.
The tests above show the effect of packet loss and latency on TCP throughput. The impact of just a minor amount (1,5%) of packet loss on a long latency path is dramatic. Using anything other than BBR on these longer paths will cause significant issues when there is even a minor amount of packet loss. Only BBR maintains a decent throughput number at anything more than 1,5% loss.
The table below shows the complete set of results for the various TCP throughput tests I did using different congestion control algorithms, latency and packet loss parameters.
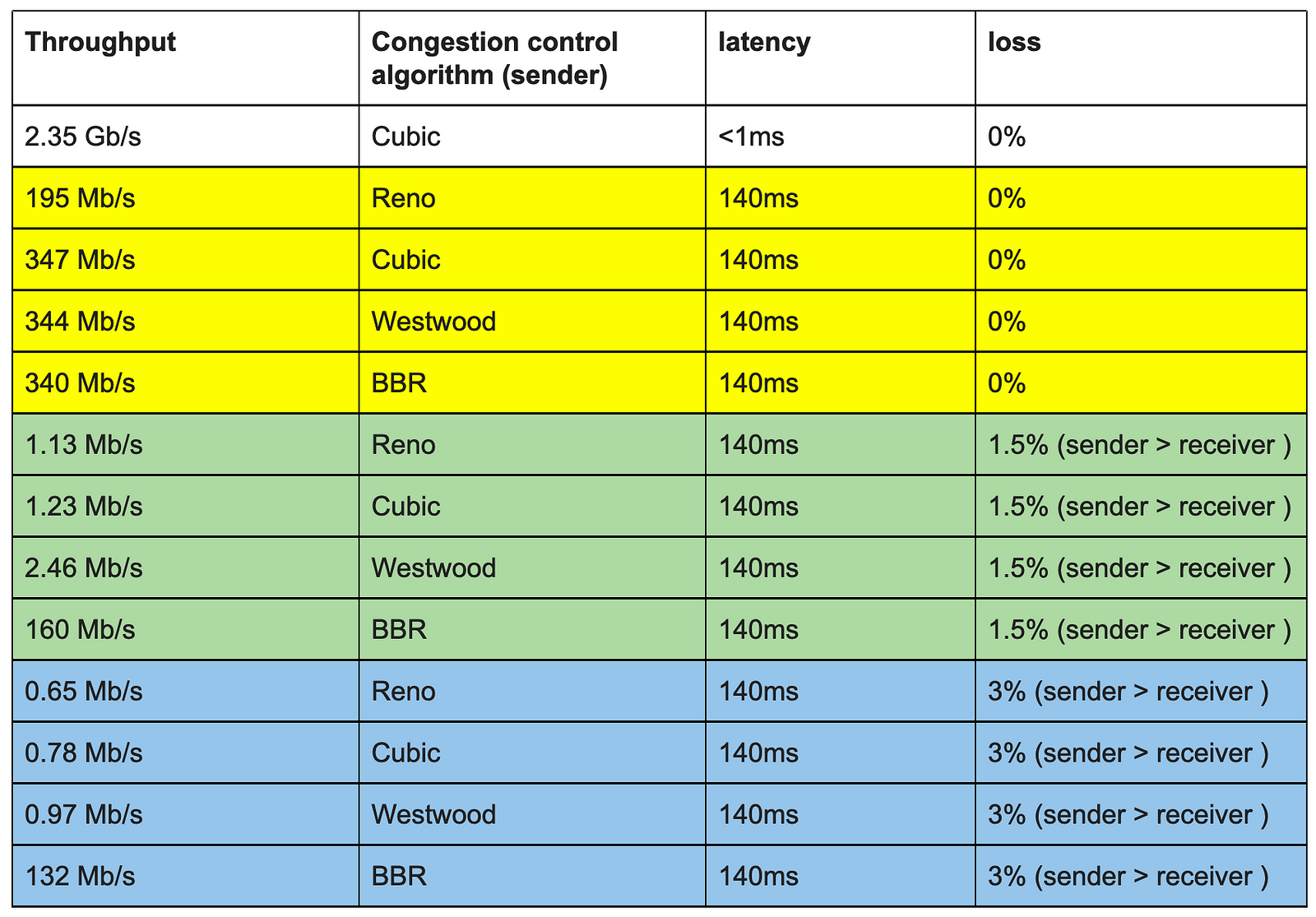
Note: the congestion control algorithm used for a TCP session is only locally relevant. So, two TCP speakers can use different congestion control algorithms on each side of the TCP session. In other words: the server (sender), can enable BBR locally; there is no need for the client to be BBR aware or support BBR.
TCP socket statistics
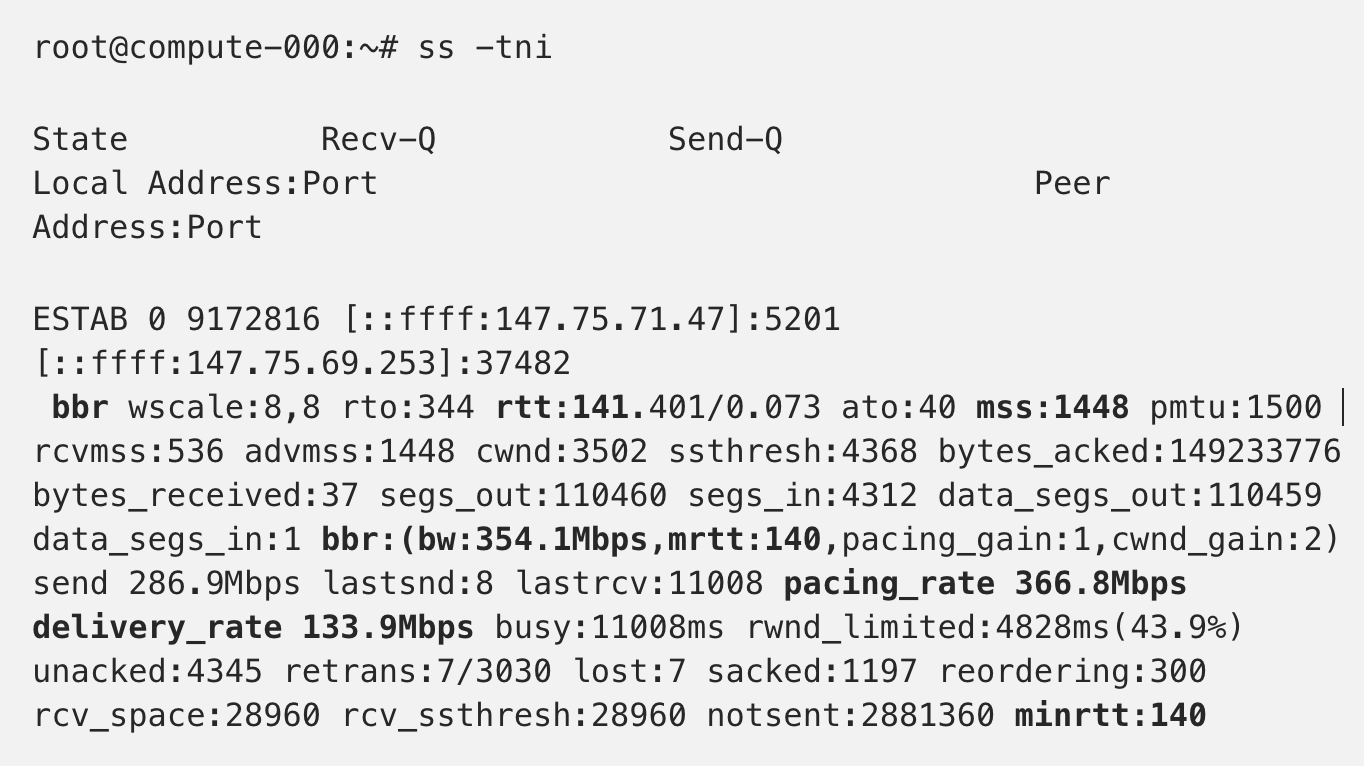
As you’re exploring tuning TCP performance, make sure to use socket statistics, or ss, like below. This tool displays a ton of socket information, including the TCP flow control algorithm used, the round trip time per TCP session as well as the calculated bandwidth and actual delivery rate between the two peers.
When to use BBR
Both Cubic and BBR perform well for these longer latency links when there is no packet loss, and BBR really shines under (moderate) packet loss. Why is that important? You could argue why you would want to design for these packet loss situations. For that, let’s think about a situation where you have multiple data centers around the world, and you rely on transit to connect the various data centers (possibly using your own Overlay VPN). You likely have a steady stream of data between the various data centers, think of logs files, ever-changing configuration or preference files, database synchronization, backups, etc. All major Transit providers at times suffer from packet loss due to various reasons. If you have a few dozen of these globally distributed data centers, depending on your Transit providers and the locations of your POPs you can expect packet loss incidents between a set of data centers several times a week. In situations like this BBR will shine and help you maintain your SLO’s.
I’ve mostly focused on the benefits of BBR for long haul links. But CDNs and various application hosting environments will also see benefits. In fact, Youtube has been using BBR for a while now to speed up their already highly optimized experience. This is mostly due to the fact that BBR ramps up to the optimal sending rate aggressively, causing your video stream to load even faster.
Downsides of BBR
It sounds great right, just execute this one sysctl command, and you get much better throughput resulting in your users to get a better experience. Why would you not do this? Well, BBR has received some criticism due to its tendency to consume all available bandwidth and pushing out other TCP streams that use say Cubic or different congestion algorithms. This is something to be mindful of when testing BBR in your environment. BBRv2 is supposed to resolve some of these challenges.
All in all, I was amazed by the results. It looks to me this is certainly worth taking a closer look at. You won’t be the first, in addition to Google, Dropbox and Spotify are two other examples where BBR is being used or experimented with.





