

Everything I’m demonstrating below can easily be replicated by using the terraform code here, with that we will have a global anycast load-balancer, and origin web & dns servers in under 5 minutes.
Global Accelerator became publicly available in late 2018, and I’ve looked at it various times since then with a few potential use-cases in mind. The main value proposition for users is the ability to get a static IPv4 address that isn’t tied to a region. With global accelerator, customers get two globally anycasted IPv4 addresses that can be used to load balance across 14 unique AWS regions. A user request will get routed to the closest AWS edge POP based on BGP routing. From there, you can load balance requests to the AWS regions where your applications are deployed. Global accelerator comes with traffic dials that allow you to control how much traffic goes to what region, as well as instances in that region. It also has built-in health checking to make sure traffic is only routed to healthy instances.
Global accelerator comes with a few primitives, let’s briefly review these:
- Global Accelerator, think of this of your anycast endpoint. It’s a global primitive and comes with two IPv4 addresses.
- Next up, you create a Listener which defines what port and protocol (tcp or udp) to listen on. A Global Accelerator can have multiple listeners. We’ll create two for this article later on.
- For each Listener, you then create one or more Endpoint Groups. An endpoint group allows you to group endpoint together by region. For example, EU-CENTRAL-1 can be an endpoint group. Each endpoint group has a traffic dial that controls the percentage of traffic you’d like to send to a region.
- Finally, we have an Endpoint, this can be either an Elastic IP address, a Network Load Balancer, or an Application Load Balancer. You can have multiple endpoints in an Endpoint group. For each endpoint, you can configure a weight that controls how traffic is load-balanced over the various endpoints within an endpoint group.
These are some basic yet powerful primitives to help you build a highly available, low latency application with granular traffic control.
Let’s start building!
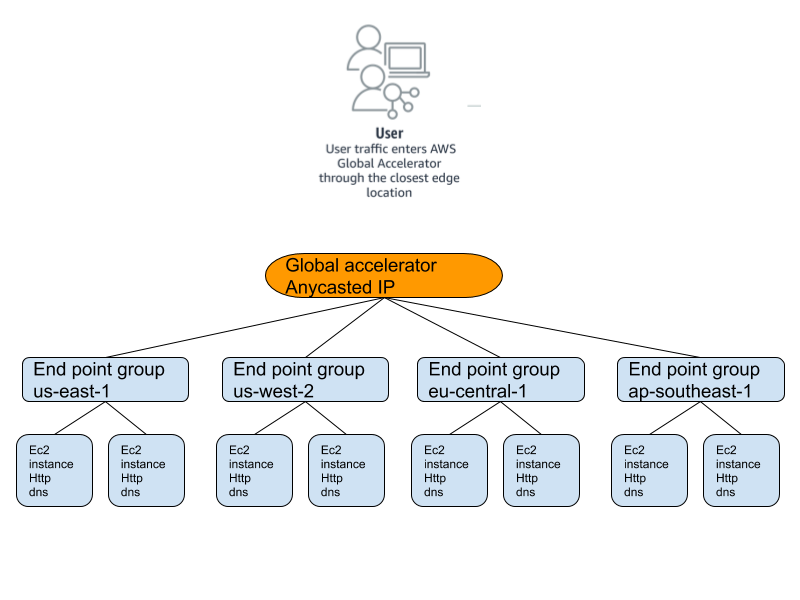
Alright that sounds cool, let’s dive right in. In this example, we’re going to build a highly available web service and DNS service in four AWS regions, us-east-1, us-west-2, eu-central-1, and ap-southeast-1. Each region will have two ec2 instances with a simple Go web server and a simple DNS server. We’ll create the global accelerator, listeners, endpoint groups, endpoints, as well as all the supporting infrastructure such as VPCs, subnets, security groups all through terraform.
I’ve published the terraform and other supporting code on my github page: https://github.com/atoonk/aws_global_accelerator. This allows you to try it yourself with minimum effort. Time to deploy our infrastructure:
terraform init && terraform plan && terraform apply -auto-approve
…
Plan: 63 to add, 0 to change, 0 to destroy.
...
GlobalAccelerator = [
[
[
{
"ip_addresses" = [
"13.248.138.197",
"76.223.8.146",
]
"ip_family" = "IPv4"
},
],
],
]
After a few minutes, all 63 components have been built. Now our globally distributed application is available over two anycast IPv4 addresses, in four regions, with two origin servers per region like the diagram below.
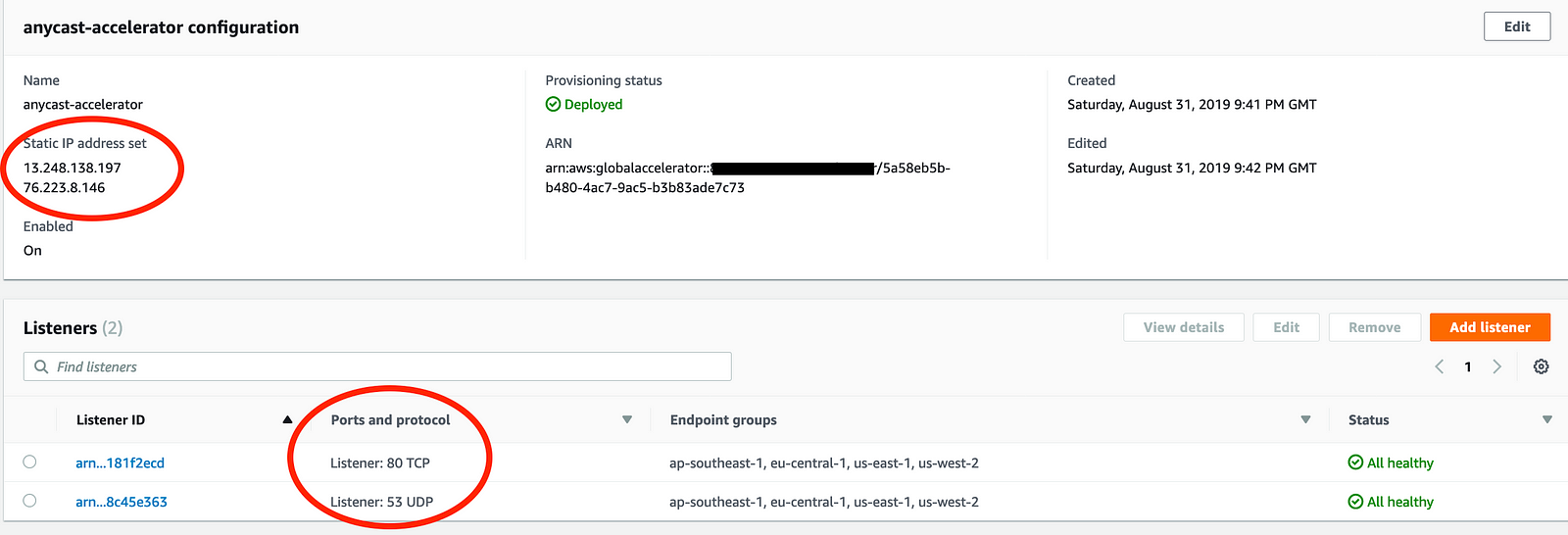
In the AWS console, you’ll now see something like this. In my example, you see two listeners, one for the webserver on TCP 80 and one for our DNS test on UDP 53.
Time to start testing.
Now that we have our anycasted global load balancer up and running, it’s time to start testing. First let’s do a quick http check from 4 servers around the world, Tokyo, Amsterdam, New York and Seattle. To check if load balancing works as expected, I’m using to following test:
for i in {1..100}
do curl -s -q http://13.248.138.197
done | sort -n | uniq -c | sort -rn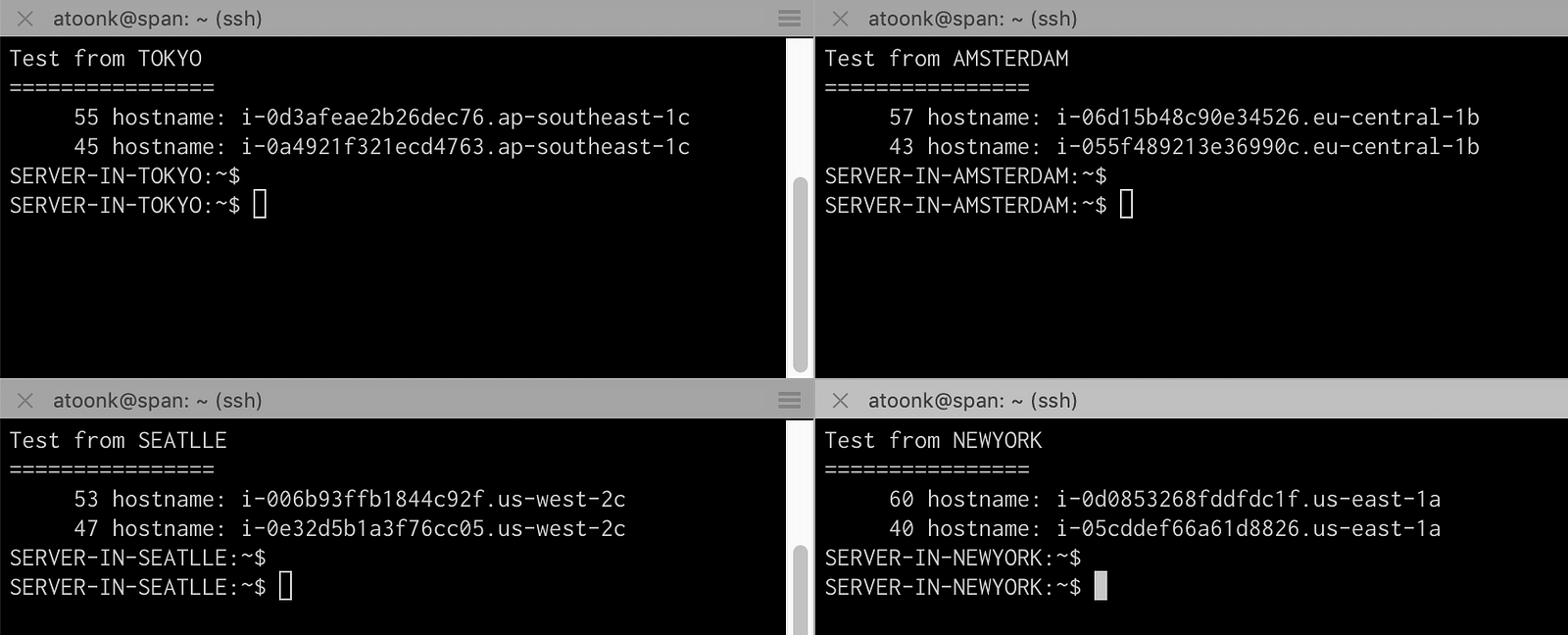
The above shows that the hundred requests from each of the servers indeed go to the region we’d expect it to go and are nicely balanced over the two origin servers in each region.

Next, we’ll use RIPE Atlas, a globally distributed measurement network to check the traffic distribution globally on a larger scale. This will tell us how well the AWS anycast routing setup works.
I’m going to use the DNS listener for this. Using RIPE Atlas, I’m asking 500 probes to run the following dig command. The output will tell us what node and region are being used.
dig @13.248.138.197 id.server txt ch +short
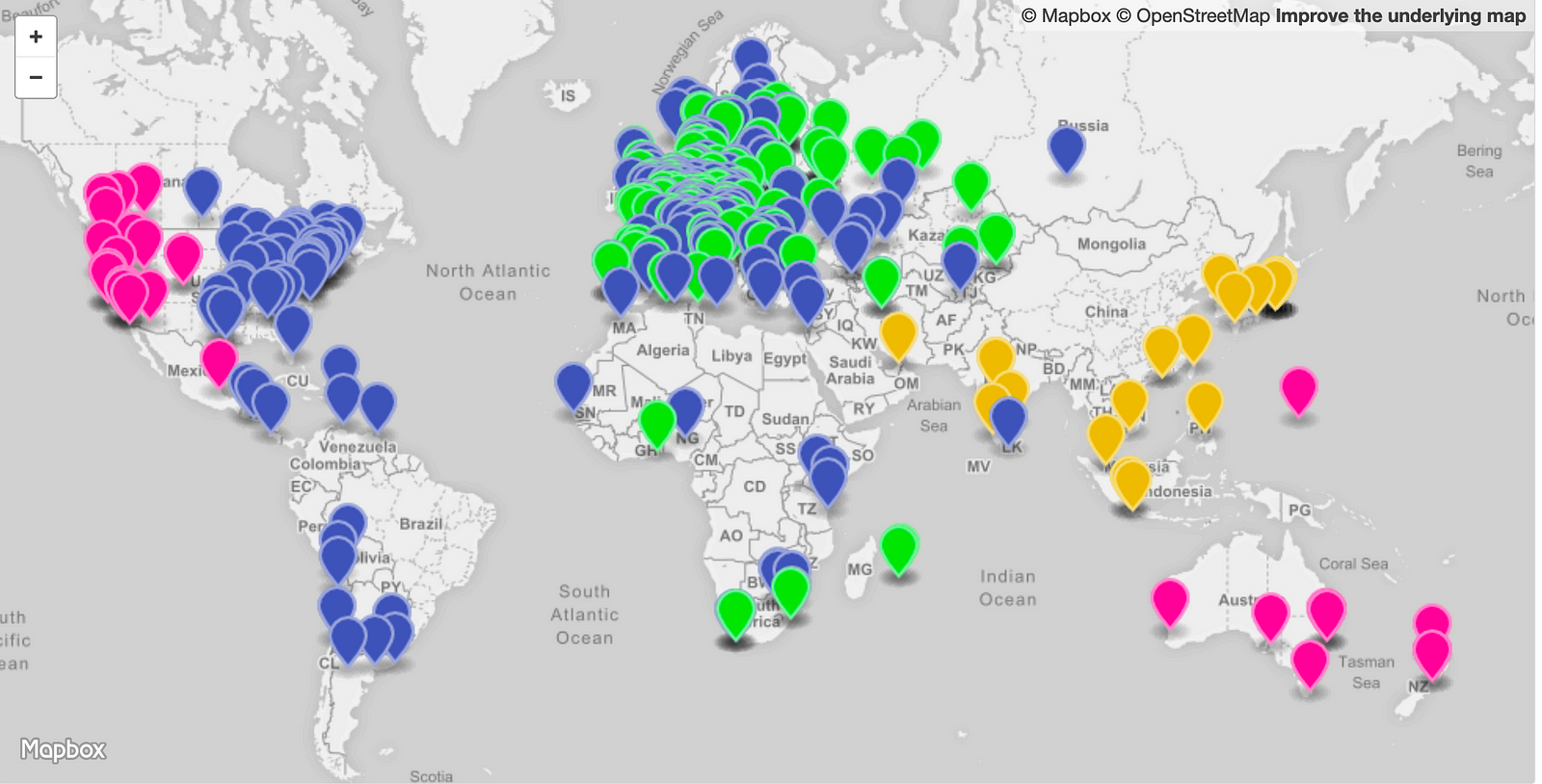
"i-0e32d5b1a3f76cc05.us-west-2c"The image below is visualization of the measurement results. It shows four different colors; each color represents one of the four regions. At first glance, there’s certainly a good distribution among the four geographic regions. The odd ones out are the clients in Australia and New Zealand, which AWS is sending to the us-west-2 region instead of the closer and lower latency Singapore, ap-southeast-1 region. I could, of course, solve this myself by creating a listener and origin server in Australia as well. Other than that there very few outliers, so that looks good.
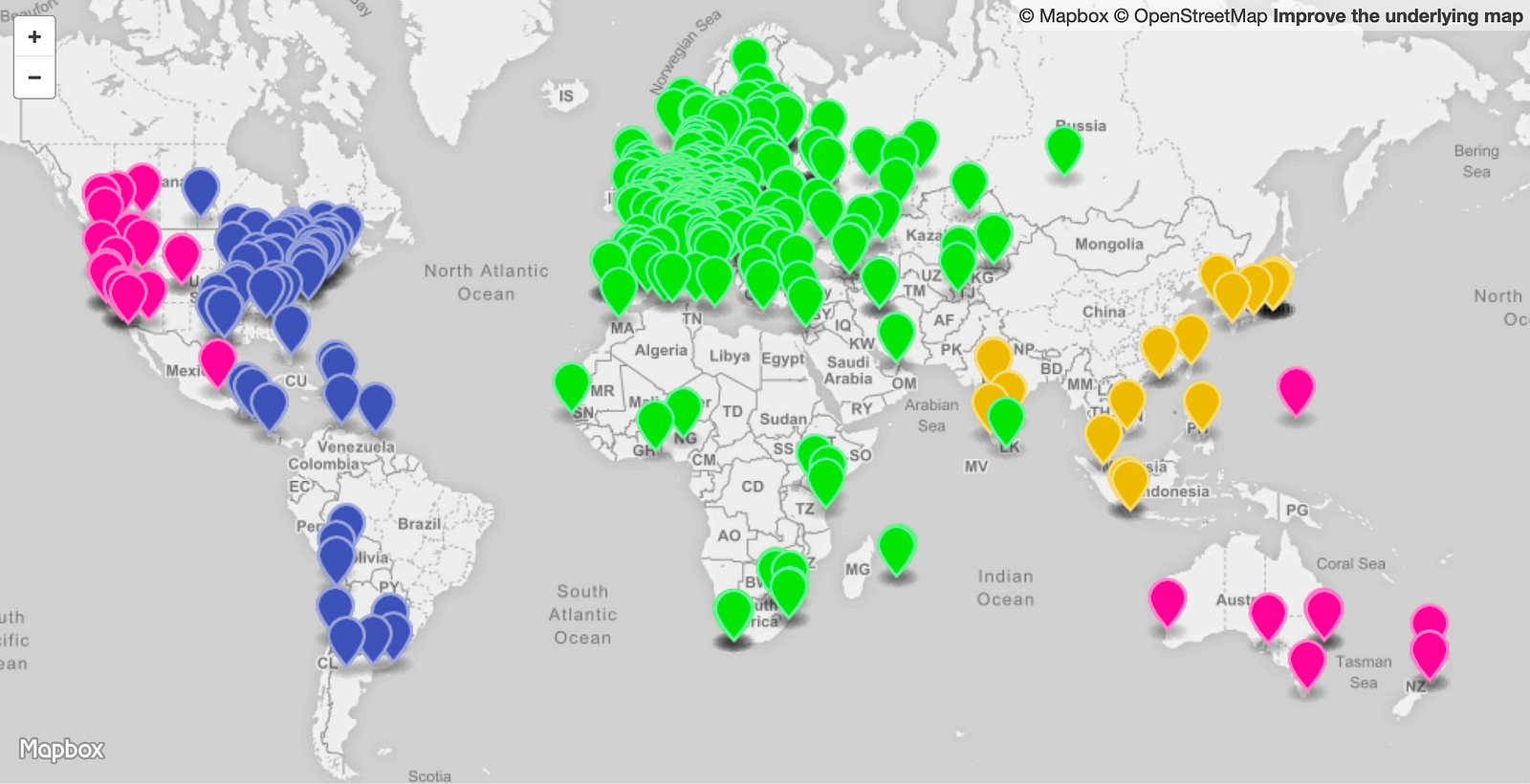
Based on this measure from 500 random Ripe Atlas nodes, We can see the region that is getting most of the traffic is the Europe region. In a real-life scenario, this region could now be running hot. To resolve that I’m going to lower the traffic dial for the Europe endpoint group to 50%. This means 50% of the traffic that was previously going to Europe should now go to the next best region. The visualization below shows that the majority of the 50% offload traffic ended up in the us-east region and small portion spilled over into ap-southeast-1 (remember, I’m only deployed in four regions).
Routing and session termination
An interesting difference between Global Accelerator and regular public ec2 IP addresses is how traffic is routed to AWS. For Global Accelerator AWS will try and get traffic on its own network as soon as possible. As compared to the scenario with regular AWS public IP addresses; Amazon only announces those prefixes out of the region where the IP addresses are used. That means that for Global Accelerator IP addresses your traffic is handed off to AWS at its closest Global Accelerator POP and then uses the AWS backbone to get to the origin. For regular AWS public IP addresses, AWS relies on public transit and peering to get the traffic to the region it needs to get to.
Let’s look at a traceroute to illustrate this. One of my origin servers in the ap-southeast-1 regions is 13.251.41.53, a traceroute to that ec2 instance in Singapore from a non AWS server in Sydney looks like this:
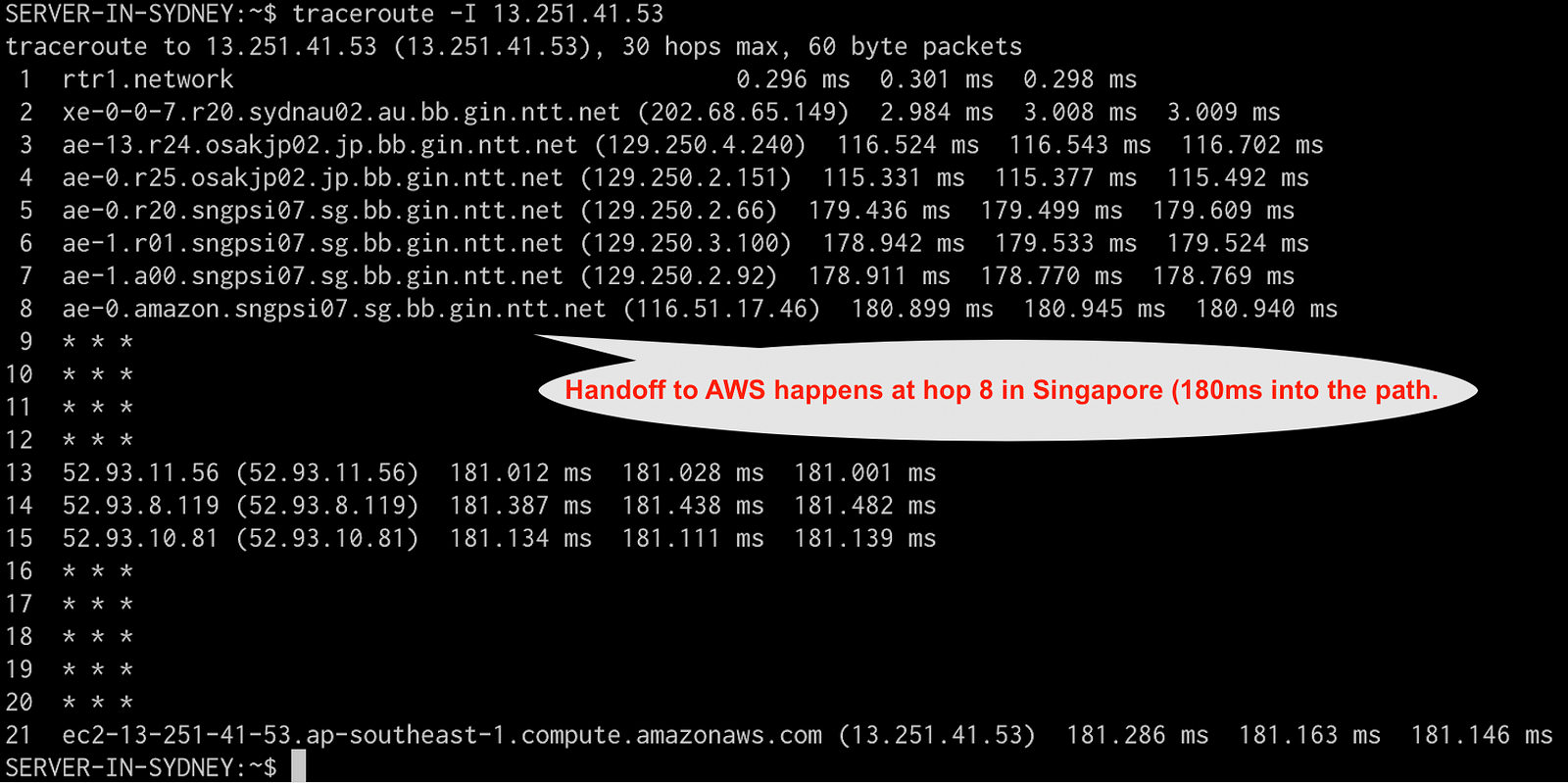
In this case, we hand off traffic to NTT in Sydney, which sends it to Japan and then to Singapore, where it’s handed off to AWS, it eventually took 180ms to get there. It’s important to observe that traffic was handed of to AWS in Singapore, near the end of the traceroute.
Now, as a comparison, we’ll look at a traceroute from the same server in Sydney to the anycasted Global Accelerator IP

The Global Accelerator address on hop 4 is just under a millisecond away. In this case, AWS is announcing the prefix locally via the Internet Exchange and it is handed off to AWS on the second hop. Quite a latency difference.
Keep in mind, although you certainly get better “ping” times to your service’s IP address, the actual response time of the application will still be dependent on where the application is deployed. It’s interesting to note though, that based on the above, AWS does appear to terminate the network connection at all of its Global Accelerator sites even if your application is not deployed there. This is also visible in the logs of our webserver, this is where we observe that the source IP address of the client isn’t the actual client’s IP, instead it’s an IP address of AWS’ Global Accelerator service. Not being able to see the original client IP address, is I imagine, a challenge for many use-cases.
Conclusion
In this article, we looked at how Global Accelerator works and behaves. I think it’s a powerful service. Having the ability to flexibly steer traffic to particular regions and even endpoints gives you a lot of control, which will be useful for high traffic applications. It also makes it easier to make applications highly available even on a per IP address basis (as compared to using DNS based load-balancing). A potentially useful feature for Global Accelerator would be to combine it with the Bring Your Own IP feature.
Global Accelerator is still a relatively young service, and new features will likely be added over time. Currently, I find one of the significant limitations the lack of client IP visibility. Interestingly, AWS just a few days ago, announced Client IP preservation for ALB (only) endpoints. Given that improvement, I’d imagine that Client IP preservation for other types of endpoints such as elastic IP and NLBs may come at some point too.
Finally, other than the flow logs, I didn’t find any logging or statistics in the AWS console for Global Accelerator. This would, in my opinion, be a valuable add-on.
All in all, a cool and useful service that I’m sure will be valuable too many AWS users. For me, it was fun to test drive Global Accelerator, check out AWS’ anycast routing setup and build it all using terraform. Hope you enjoyed it too :)





